0x1 VVC
VVC是Versatile Video Coding的简写,也称为H.266,是下一代视频压缩标准,VVC已经于今年7月份完成标准的制定。VVC虽然没有突破传统的block based hybird的视频编码架构,但是借助于各种coding tools优化效果的累积效果,其编码效率比上一代视频压缩标准HEVC提升50%左右,也就是说VVC和HEVC达到相同的编码质量,VVC的码率能比HEVC节省50%。
对于VVC中的各种coding tools,笔者会在后续的文章中介绍。
本文介绍一下VVC标准中没有包含的一种coding tool,就是借助于Neural Network来优化视频压缩的方法。在VVC的多次会议的提案中都包括了借助于Neural Network来优化视频压缩的方法。至于这些提案最后没有进入标准,一个原因是这些方案的压缩效率提升不少很明显,而且适用范围有限。另外也可能和计算的复杂度有关,例如有些提案在CPU上的解码时间会增加好几倍。笔者觉得对于未来的视频标准(H.267?)来说,可能会采纳类似的方案,也许那个时候GPU解码会成为标配,为了追求极致的压缩效率,复杂度的增加也许会变得可以接受。
笔者分析了VVC提案中Neural Network的有关提案,发现基本集中在Loop Filter部分较多,这个和目前热门的Super Resolution技术解决的问题类似,也就是通过NN的方法把图像中失真的信息尽量还原回来,VVC中失真是指通过编码器量化过程以后,码流中包括的信息和源图像是有失真,而NN Filter可以很好的完整失真信息的还原。
另外VVC的提案中也包括了采用Neural Network来优化Intra Prediction和Rate Control编码效率的方案。
下面对VVC中有关Neural Network的提案进行总结归类。
0x2 关于Neural Network based Loop Filter的提案
Neural Network based Loop Filter的提案又包括了下面这几种。
0x21 JVET-I0022 Convolution Neural Network Filter (CNNF) for Intra Frame
0x211 JVET-I0022 Convolution Neural Network Filter (CNNF) for Intra Frame (Hikvision)
VCC中包括了BF/DF/SAO filter这几个传统filter,这几个filter的作用是remove artifacts or improve coding performance。
CNNF用于替换这些传统filter。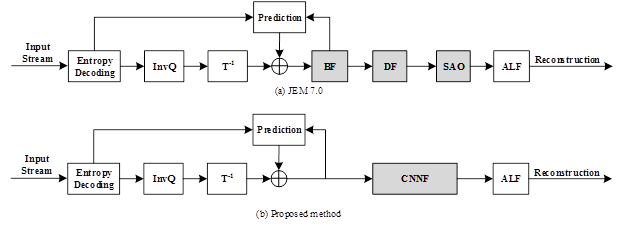
网络结构如下图所示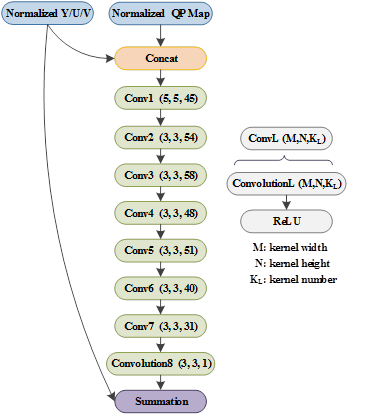
0x212 JVET-J0043 Convolutional Neural Network Filter for inter frame (Hikvision)
为了避免over-filter造成artifacts,采用RDO方法来选择是采用传统的Filter还是CNN filter。选择filter的flag通过CABAC编码。
0x213 JVET-N0169 Convolutional Neural Network Filter (CNNF) for Intra Frame (Hikvision)
对CNNF放置在deblocking的不同位置的编码性能进行比较。
Comparison of intra decoding scheme between different positions of CNN filter
优化结论如下。
Driven by the advances of deep learning, a CNN-based filter for intra frame is proposed to remove the artifacts. Simulation results report -3.48%, -5.18%, -6.77% BD-rate savings for luma, and both chroma components for VTM-4.0 with AI configuration as the CNNF before the SAO. As the DF and SAO are turned off, the CNNF brings -4.65%, -6.73%, -7.92% BD-rate savings with ALF behind. Even though all the conventional filters are turned off, the CNNF still brings 4.14%, -5.49%, -6.70% BD-rate savings.
0x214 JVET-K0158 Separable Convolutional Neural Network Filter with Squeeze-and-Excitation block(Sharp)
对JVET-I0022进行进一步优化,减少CNN网络参数,可以达到和JVET-I0022类似的编码优化效果。
0x22 JVET-K0222 Convolution neural network loop filter (MediaTek)
设计了CNN Loop Filter,对reconstructed samples进行loop filter处理。
如下描述,这个CNN的parameter是在encoder的过程中通过online的方式生成的。 不像其他几种提案完全是通过offline的方式来生成。
only those pictures with temporal ID equal to 0 or 1 are used to derive CNNLF parameters in the training process. That is, only these pictures are required to be encoded twice. The first round is to generate the required data for CNNLF training process and derive the CNNLF parameters. The second round is to generate the final bitstream by enabling CNNLF with the derived parameters.
如下图所示,这个CNNLF添加在adaptive loop filter (ALF)的后面, CNNLF的输入是ALF输出的reconstructed samples。CNNLF的输出被称为 restored samples.

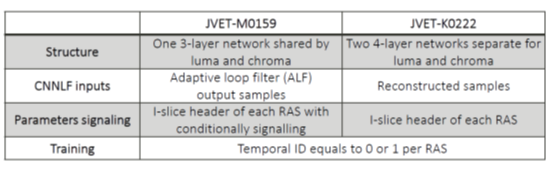
JVET-M0159, Convolutional neural network loop filter (MediaTek)
其对K0222进行了优化,主要是简化NN网络。JVET-M0159和JVET-K0222的差异如下。
0x23 JVET-K0391 Dense Residual Convolutional Neural Network based In-Loop Filter (Tencent, WHU)
在SAO前面加入dense residual convolutional network based in-loop filter (DRNLF)
In-loop filters, such as DF (deblocking filter), sample adaptive offset (SAO), are employed in VTM for suppressing compression artifacts, which contributes to coding performance improvement.
In this contribution, the proposed DRNLF is introduced as an additional filter before SAO
Proposed decoding scheme in VTM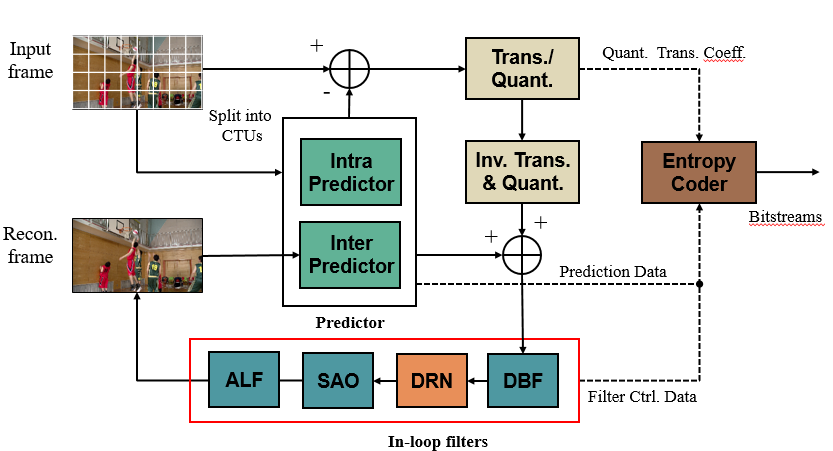
JVET-L0242 Dense Residual Convolutional Neural Network based In-Loop Filter(Tencent, WHU)
JVET-L0242对JVET-K0391进一步优化,减少了NN网络的参数。另外为了防止over-filter,采用如下图所示的RDO方法来决策是否采用DRN。
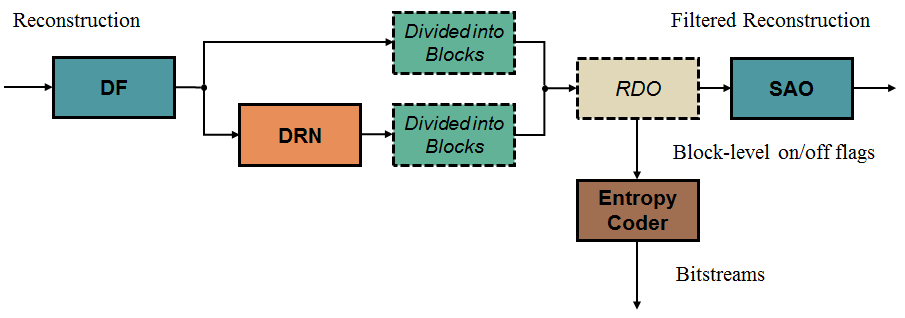
0x24 JVET-L383 Convolution Neural Network Filter(KDDI)
提案也是采用Convolution Neural Network Filter去替换目前的multiple filter such as deblocking filter (DBF), sample adaptive offset (SAO) and adaptive loop filter (ALF)。另外CNN Filter参数在encoder端和decoder端是相同的。
优化结论如下。
The simulation results show the BD-rate for luma is -0.93% for AI where CNNF is replaced by DBF, SAO and ALF though the BD-rate is -2.21% for AI where CNNF is replaced by DBF and SAO only.
The filter structure is shown in Figure 1. This filter has four layers with 3x3 taps. The input of sum block is residual signal from the left and reconstructed signal before all in-loop filters from the bottom. The output of sum block is filtered pixels. Actual output is weighted sum of after filtered and before filtered pixels based on the distance of edge.
提出的CNNF的结构图如下所示。
0x25 JVET-M0510 CNN-based In-Loop Filter proposed by USTC
这个提案中提出的CNN filter具有如下特点。
- Lightweight deep convolutional neural networks
- Locate between DF and SAO
- -0.96%, -0.32%, -0.45% BD-rate savings for Y, Cb, and Cr components compared with VTM3.0 under AI configuration
0x26 JVET-M0566 Adaptive convolutional neural network loop filter (Intel)
该提案提出了ACNNLF的设计,通过online training的方式得到3 CNN based loop filters。每个filter都是a small 2 layer CNN with total 692 parameters。在编码过程中为每个CTB的luma、chroma选择3个ACNNLFs之一作为loop filter。这三个ACNNLFs的网络参数会被写入到slice header中,然后每个CTB要选择哪个ACNNLF的话,只需要一个index指定到slice header的ACNNLFs的网络参数即可。
ACNNLF在解码流程中的位置如下图所示。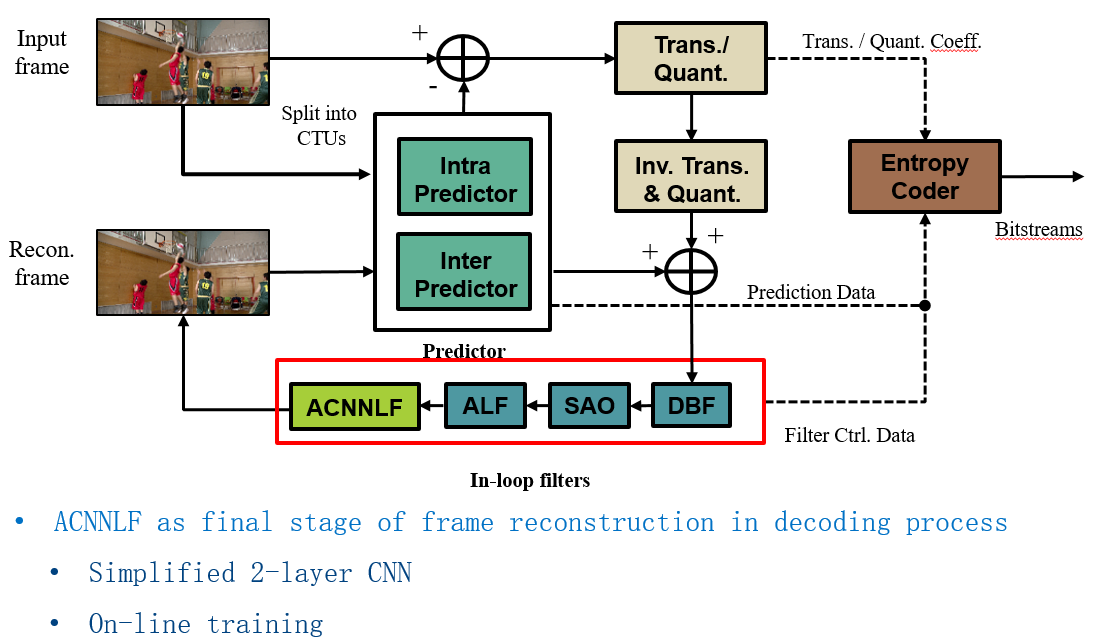
下面说明了ACNNLF的设计思想,主要体现了adaptive的online training的思想。
The ALF filter can be considered as a special one-layer CNN with linear activation. However, the number of filter coefficients in an ALF filter is too small to capture relevant features in the video. In order to match different video content, many ALF filters are used. Therefore, ALF makes up the deficiency of small number of filter coefficients by increasing the number of filter classes used.
As we try to further reduce the number of CNNLF parameters, we increase the number of CNNLFs to choose from to ensure the design can adapt to diverse video content without sacrificing performance. In this document, we propose an ACNNLF design:
- Small Deep-CNN loop filter with minimum number of hidden layers (2 CNN layers);
- 3 set of CNN loop filters trained online for luma and chroma respectively to better adapt to the content.
Since the number of ACNNLF filters (3) is small, it is possible to conduct exhaustive search for the optimal ACNNLF in the encoding process. The ACNNLF selection is indicated in the coded stream to the decoder. ACNNLF is applied after ALF in the decoding process.
采用了ACNNLF的优化结论如下。
This contribution presents an ACNNLF design with 3 classes of CNN based loop filters, where each filter has only 2 CNN layers and 692 parameters. The 3 ACNNLFs are adaptively trained with video sequence data. The best ACNNLF is selected for luma and chroma respectively for each CTB at encoder and indicated to decoder in coded stream with 2 bit indicator at CTB level. Compared with VTM-4.0-RA, the proposed ACNNLF achieves -1.14%, -0.21%, and -1.18% BD-rates for Y, U, and V, respectively, for Class A1 video sequences; -0.98%, -14.37%, and -16.96% BD-rates for Y, U, and V, respectively, for Class A2 video sequences; -0.55%, -21.79%, and -20.04% BD-rates for Y, U, and V, respectively, for Class B video sequences; and 0.09%, -2.75%, and -1.43% BD-rates for Y, U, and V, respectively, for Class C video sequences. The decoding time in the RA is 127% on VTM 4.0.
0x27 JVET-O0079 Integrated in-loop filter based on CNN (Tests 2.1, 2.2 and 2.3)
Northwestern Polytechnical University (NPU), Xidian University, Guangdong OPPO Mobile Telecommunications Corp., Ltd
提出采用WSE-CNNLF(Wide-activated Squeeze-and-Excitation Convolutional Neural Network Loop Filter)作为in loop filter,具有下面的特点。
- It includes six inputs: three reconstructed components (Y, U, V) and three auxiliary inputs (QPmap, CUmap for luma, CUmap for chroma).
- It consists of three stages to make the luma and chroma components jointly processed and separately fused with the corresponding CUmap before generating outputs.
- It can replace and even outperform the multiple filters in current VVC.
Main structure of the proposed CNNLF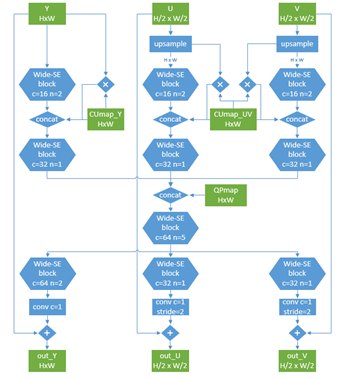
该提案的优化结论如下。
For test 2.1, it can be seen that converting weights from 32bit-float to 8bit-int leads to lower gains (from -0.46% to 0.79% for BD-rate saving on luma).
For test 2.2, in AI configuration, the BD-rate saving on luma of in-loop filter (-3.93%) is higher than that of post filter (-3.05%). In RA configuration, the BD-rate saving on luma of post filter (-1.89%) is higher than that of in-loop filter (-0.26%). It is noted that the proposed NN filter completely replaces the original in-loop filter (i.e., DBF+SAO+ALF ) when test 2.2a is performed to evaluate the in-loop situation, while it is added as a post filter with DBF+SAO+ALF all on in 2.2.b. It is concluded that the proposed NN filter reportedly outperforms DBF+SAO+ALF if used as the only in-loop filter, and is also useful if used as an extra post-loop filter.
For test 2.3, it’s shown that the proposed WSE-CNNLF has generalization capability on higher QP. The BD-rate saving is -0.46%, -4.11%, -2.80% when the test QP is the same as training QP, and -1.52%, -6.15%, -4.31% when the test QP equals to training QP+5. The CNN-based loop filter seems to be more effective on lower video qualities.
0x3 采用Neural Network来加速CTU partition加速和优化编码效率
JVET-J0034 CNN-based driving of block partitioning for intra slices encoding
该提案的算法描述如下。
for driving the encoder by estimating probabilities of blocks or Coding Units (CU) splitting in intra slices. The approach is primarily based on a texture analysis of the original blocks, and partly replaces the costly Rate Distortion Optimization (RDO) potentially involved for testing all potential partitioning configurations.
Overview of the split prediction process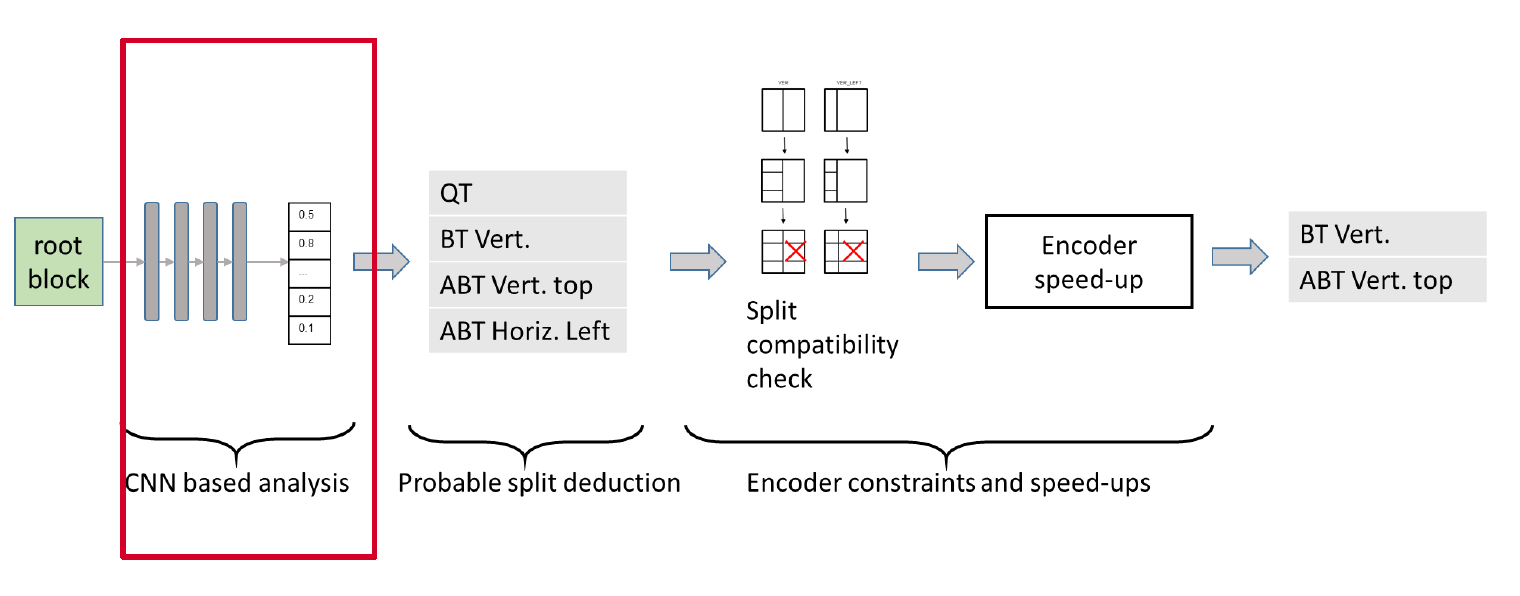
This module precedes the usual RDO process, and pre-selects the split configurations to be tested by the RDO. It is composed of the following 3 steps:
- CNN-based analysis – In the first step, each input 65×65 patch is analyzed by a CNN-based texture analyzer. The output of this step consists in a vector of probabilities associated to each one of the elementary boundaries that separate elementary sub-blocks. Figure 2 illustrates the mapping between elementary boundary locations and the vector of probabilities. The size of elementary blocks being 4×4, the vector contains n=480 probability values. The CNN is described in section 3.
- Probable split selection – The second step takes as input the probability of each elementary boundary and outputs a first set of splitting modes among all possible options, which are: no split, QT, BT (vertical, horizontal), ABT (top, bottom, left, right). This step is further detailed in section 4.1.
- Encoder constraints and speed-ups – The third step selects the final set of splitting modes to be checked by classical RDO, depending on the first set provided by step 2, the contextual split constraints described in JVET-J0022 section 3.1.1.3 and the encoder speed-ups described in JVET-J0022, section 3.1.2.1. This step is further detailed in section 4.2.
该提案的优化结论如下。
在AI configuration情况下,在相关的编码时间情况下,比基准(JEM7)取得6%的BD-rate gain,在相同的BD-rate gain情况下,编码时间可以减少4.3倍。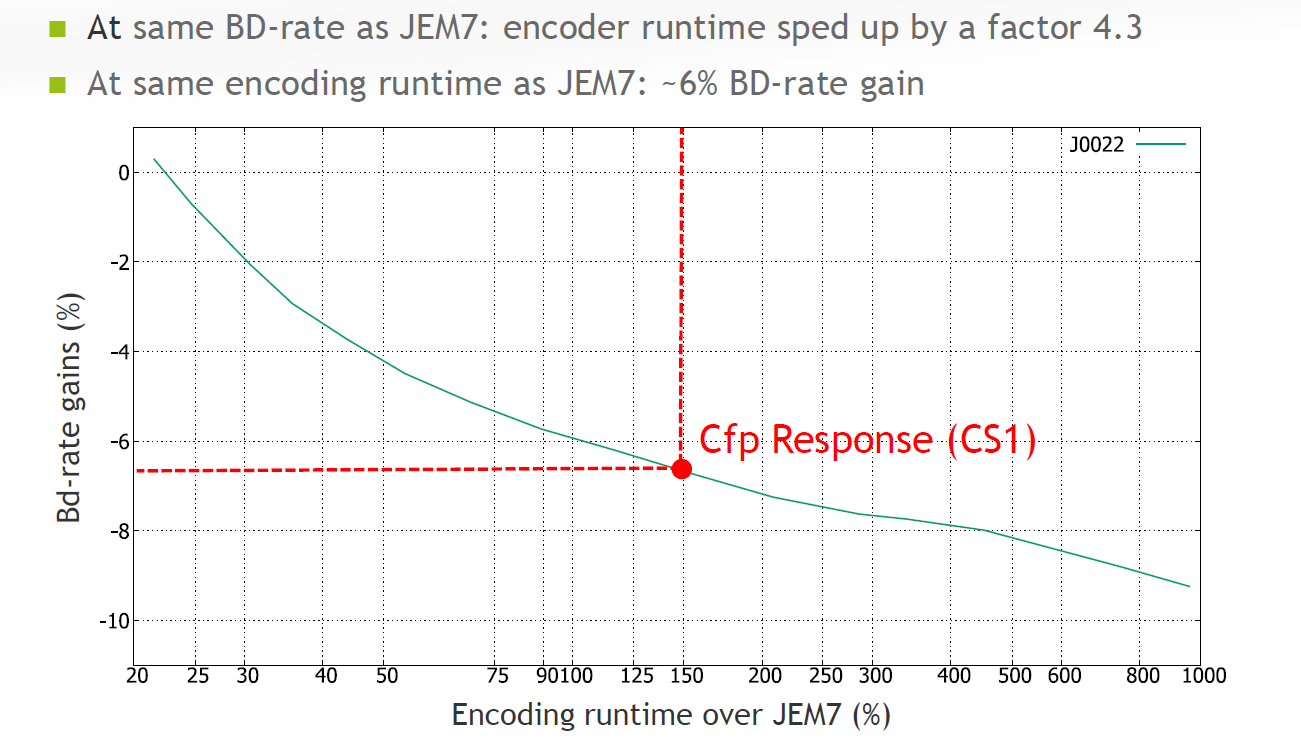
0x4 采用Neural Network来优化Intra Prediction
JVET-J0037 Intra prediction modes based on neural networks
如下图所示,通过NN的方法来得当前Intra block的预测像素值。
Prediction of MxN intra block from reconstructed samples using a neural network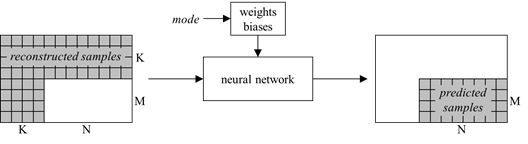
如下图所示,通过NN的方法来得当前Intra block的预测mode值。
Prediction of mode probabilities from reconstructed samples using a neural network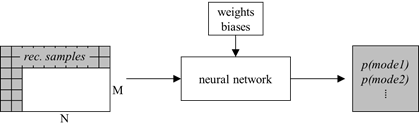
0x5 采用Neural Network来优化Rate Control
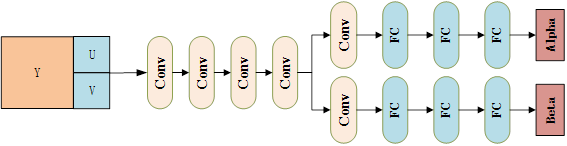
JVET-M0215 CNN-based lambda-domain rate control for intra frames
This contribution proposes a CNN-based λ-domain rate control approach for intra frame coding. Compared with the exiting SATD-based intra rate control approach in VTM, we reuse the R-lambda model in VTM inter frame rate control and train one convolutional neural network to simultaneously predict the two model parameters, alpha and beta. Compared with the rate control method in VTM 3.0, the proposed method can achieve an average bd-rate reduction of 1.8% under All Intra configuration. When considering the mismatch between target bitrate and actually coded bit rate, the CNN-based method can achieve a smaller rate control error, especially for the first I frame.
通过下面的NN网络训练得到两个参数,这两个参数作为Rate Control的后续输入参数。
We propose to reuse the model and train one convolutional neural networks to simultaneously predict the two parameters. The network architecture is depicted in Fig.1. Specifically, before the encoding for one Intra frame, we extract the luma component, as well as the chroma components of each CTU and feed them into the two trained CNN, from the CNN output we can obtain the corresponding and for each CTU.
CNN-based rate control的网络结构图如下所示,从图中可以看到是用一个网络来预测两个参数。
0x6 有关Neural Network的参数传递
JVET-N0065 Comments on carriage of coding tool parameters in Adaptation Parameter Set
采用Adaptation Parameter Set (APS)用于动态传输neural network的参数。
In 13th JVET meeting, Adaptation Parameter Set (APS) has been introduced into Versatile Video Coding (VVC) standard text. A few years ago, the APS was once adopted into High Efficiency Video Coding (HEVC) standard for carrying coding tool parameters, such as Adaptive Loop Filter (ALF) parameters; but the APS was removed from HEVC standard along with the removal of ALF as a coding tool at a final HEVC standardisation stage. The APS was designed to carry coding tool parameters as a picture level adaptive nature and alternatively the APS data can also be maintained as unchanged for the whole video sequence for avoiding resending them unnecessarily. This contribution is for information only and it is commented and recommended to use the APS to carry the coding tool data, such as neural networks parameters and affine linear weighted intra prediction parameters, etc., if some associated coding tools are indeed to be adopted into VVC standard. If more coding tool data need to be carried by APS in the future, it commented that further study on updating parameters of multiple tools using APS would be needed.
It is recommended that APS can be considered as the carrier for coding tool parameters, such as neural networks coding parameters, etc., to convey these parameters in bitstreams to a VVC decoder. When more types of coding tool parameters are needed to be carried by APS, updating parameters of multiple tools using APS would need to be further studied for achieving more efficient use of the APS.